Authoring Expressions
Expressions Overview
The ArticulateML node returns extracted output, formatted as JSON objects. Refer to the documentation on Response Syntax for an overview of that output. ArticulateML leverages a JSON transformation language called JSONata for parsing and formatting data into field data GlobalCapture can understand. Users who will be writing extraction expressions should familiarize themselves with the basics of JSONata here. There is also a JSONata expression test tool, found here, where user’s can experiment with the language.
Reserved Words
Expressions CAN NOT contain user defined variables, or other random text, that matches the reserved words list. Reserved words include:
$row
$toi
Note, this includes keywords found within other strings. For example, a user variable name $rowIndex is invalid as it contains a reserved word. No reserved words should be used outside of their specific use cases, which are documented elsewhere on this page.
$toi is a replacement variable
When table expressions are evaluated, any occurrence of the string $toi will be replaced with the expressions provided in the Table AI Table of Interest field. This essentially allows for shorthand notation to reference that part of the expression without having to rekey it, potentially multiple times, in more complex expressions and / or functions.
When mapping values to table fields, with a properly formed Table of Interest, expressing the rest of the statement can be significantly simpler and less error prone. Use of this replacement is highly encouraged.
Table of Interest should express a singular table’s rows
The node has a setting for identifying the table of interest. The system understands how many rows to inspect based on this expression. It MUST represent only one table, and that table must have at least one row for table extraction to be performed. The last segment for any expression provided here should end with “.rows” as in this example:
tables[table.rows.columns[value~>/item/i]][0].table.rowsIn the example, we guarantee only one table would ever be returned by expressing element zero of the tables collection.
Use the AI’s Table of Interest to control the number of table rows
GlobalCapture attempt to perform table mapping for each row identified by the table of interest. In general terms, expect a row in the resulting table for each row identified by the ToI expression. If your ToI has no rows, the table will be empty. After that, it should be 1:1 unless there is some kind of error which would need to be identified and resolved in testing.
The may be times where the AI extracted tables have more rows than you want or need. This can happen for a number of reasons, but most often it will be because “empty” rows were found and reported. If empty rows are not filtered, you may wind of up with rows, or extra data you did not intend to collect.
In an example like the following, you might expect to read a single row:
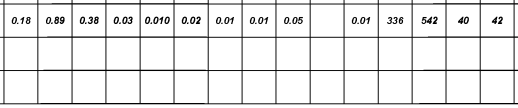
Because of the document layout, the AI extraction will more likely read 3 rows, 2 of which would be empty. An expression like the one below could be tuned to only return rows containing the data we care to map by ensuring that only rows that have a value in column 1 are returned.
tables.table[tab_index=1].rows[columns[col_index=1 and value != ""]]It is a good idea to consider only values that are not empty
As outline above, extra empty rows may be present in a result. Row counts in the ToI impact how many times capture will loop through an expression on table data. If you don’t want a table with empty or otherwise nonsensical rows, be sure to only have rows in the ToI that include data that correctly represents the row count.
$row is a replacement variable
For table field processing, $row is an internal variable that will be replaced with the index of the current rowing being processed. All occurrences of the variable get replaced with the row index.
This allows for complex expressions to be written in the test tooling that require minimal change when set in the node. Consider the expression:
(
$row:=20;
$standard := header_footer[key~>/b01 standard/i].value;
$item := $string(tables.table[tab_index=1].rows[row_index=$row].columns[col_index=1].value);
$standard &
" | " &
tables.table[tab_index = 1].rows[row_index=$row].columns[col_index=2].value &
" | " &
tables.table[tab_index=0].rows[columns[col_index=1 and value=$item]].columns[col_index=2].value;
)Row 20 is statically set in this test expression. Simply removing the assignment of “$row:=20” will allow this expression to function inside of GlobalCapture.
Data is collected PER PAGE
This means the data set is aggregated as we iterate the pages of a document. The node expects only one document per process. NEVER attempt to process multiple different documents in a single file. Each page is processed independently and in order. Multi-page documents should be thoroughly tested to be certain expressions do not pick up data from pages other than those intended.
The GlobalCapture Node, by default, only processes page 1. You should not turn on multi-page processing unless you are certain it’s necessary. When you enable multi-page processing, ALL pages are read and extracted.
Be advised that extracting all pages without a specific need can lead to accuracy and quality issues, and additional costs.
Header fields are overwritten, tables are appended
When working with expressions, it’s possible for the same field to be targeted multiple times, or it’s possible for the same document to be processed through different nodes in the same workflow. Design users should understand how field data is edited by the node during processing.
Traditional header/footer fields are always overwritten. If you target the same field in a single node with multiple expressions, or if you target the same field with multiple nodes in the same workflow, expect data to be overwritten in this type of field.
If an expression does not return a value, the field is not cleared. Instead it will be skipped, and a message is logged to the history suggesting the field could not be written. Note that this does not mean that all expressions could not find data to write into the field.
Table rows are always appended into the target table.
Table ID’s can shift / change due to page anomalies
When expressing table data, it should be understood that table ID’s might shift. This would typically only happen in cases where anomalies in the document create enough variance for a table to get missed, thus shifting the tables. With this in mind, depending on the application, you may wish to alter expressions to be less rigid.
For example, if your document result consistently represents the data of interest in a table with an ID of 1, on might express that as:
tables.table[tab_index=1]
If however you find table ID’s shifting because of document variances, you might want to reference a table by a value, perhaps in it’s header. In this case, if you can identify data in a header that is always unique (and ITEM column for example), if may be expressed as:
tables[table.rows.columns[value~>/item/i]].table
In the above, we are filtering the tables collection to include only tables that have a row which includes a column that has a value containing the pattern “item” in case insensitive form. You could further refine the filter with additional parameters to fit the specific need. You may, for example, wish to restrict the filter to find the pattern only in the first row (the header) of the table.
Filters can be nested
It can be easy to skip over important parts of an expression when just getting started. When using a filter to target table specifically, it’s can be easy to miss the fact that column values need to be filtered in square brackets, even within another filter. Using the example above, a common mistake would be to write the expression as:
tables[table.rows.columns.value~>/item/i][0].tableThis expression will not evaluate, or evaluate properly. Since you are filtering the columns object, within the tables filter, another set of square brackets is required within the expression.
tables[table.rows.columns[value~>/item/i]][0].tableControl the length of expressions with $join()
It is not uncommon to collect multiple data points from a table into a single field. While it is possible to write multiple, discrete expressions and concatenate their values, for objects in a single row, the $join function can simplify things. For example, if you wanted columns 1 and 2 from a document’s table in a single field, it could be expressed as:
tables.table[tab_index=1].rows[0].columns[col_index=1].value & " " &
tables.table[tab_index=1].rows[0].columns[col_index=2].valueWhile valid, the expression itself is lengthy and can be simplified with $join, as in:
$join(tables.table[tab_index=1].rows[0].columns[col_index=1 or col_index=2].value, " ")The first expression uses multiple complete statements and concatenates the values using the “&” character. Without using $join, the second expression will return a JSON array containing the values from both cells. The use of $join combines the array values into a single string, separated in this case by a space.
You may need to reform the returned data (advanced)
There may be times when the data returned requires manipulation to achieve the desired outcome. While an advanced topic, it is achievable to reform data into the expected format for GlobalCapture to process it. Consider the following table:

In such an example, the cell’s result would have a single value for each row. Something similar to:
{“value”:”PO2J6,P84J6,P81J6…”}
Row processing is driven off the rows collected from the expression in the Table of Interest. To process each element in this collection as row, the string will need to be broken into individual elements and the output reformed to match what GlobalCapture expects the table format to be, as defined in the response syntax documentation.
Complex headers or layouts may result in extra columns in tables
There will be times when a tables layout is not clear, and while it might be logically defined to the human eye, the AI extraction may result in extra columns of data as a result. In the example below, the table’s proximity the table above it, and it’s lack of defined columns for ITEM, SCH., and NPS results in additional empty columns in the result.
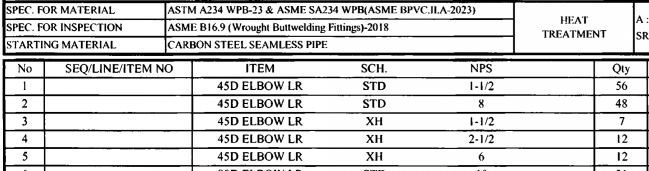
The data output for a row in this example might resemble “1,,45D ELBOW LR,,STD,,1-1/2,,56”. Using this knowledge, it can at times be helpful to identify the specific index of a column in your expression so you might explicitly target the column of columns of interest. For example, if you wanted to capture the ITEM, SCH., and NPS columns to a single field, you might try identifying the column index of “SEQ/LINE/ITEM NO” and of “Qty” and getting everything in between.
$col_qty:=tables.table[rows.columns[col_index=1 and value~>/^no/i]][0].rows[row_index=1].columns[value~>/qty/i].col_index;
$col_item:=tables.table[rows.columns[col_index=1 and value~>/^no/i]][0].rows[row_index=1].columns[value~>/seq/i].col_index;
$join($toi[row_index=$row].columns[col_index>=$col_item+1 and col_index<$col_qty].value, " "); It is possible for some table layout to not recognize as tables
The most successful table extraction comes from clearly defined tables. We recommend you DO NOT perform image clean up steps that drop lines or borders from tables. Particularly when there is only a single row of data, a lack of table structure can result in data you expect to be in table form showing up in header elements.

% references the parent object of your current location in the tree
Using %, you can reference objects up one level in the tree. This can be helpful when using complex expressions. % is essential a shorthand notation. You could fully express nested statements like the one below, but using % creates a less confusing and more legible expression.
tables.table[rows.columns[value~>/type$/i]].rows[row_index>%.rows[columns[value~>/type$/i]].row_index]Parenthesize expressions to create ‘code blocks’
Expressions can be wrapped with parens. You can use this concept to create expression blocks, where the output of the last expression in the block is what gets returned. Note that all expressions in a block must be terminated with a semicolon.