GlobalSearch can convert documents being captured to an Archive into text-searchable PDF format through its optional Full Page OCR module. Use of this feature in GlobalSearch also requires a Content Search license and that Archives are Content Search enabled. Regardless of whether your document is a scanned, imported, or dragged into an Archive, documents are automatically converted behind the scenes. This feature does not convert documents that already texted-based, such as the DOCX file format. However, it will redo the OCR process for any PDFs that may already be text-searchable on each save operation. Keep this in mind, as it can have a significant impact on performance and document access.
Document types that are converted to PDF are: JPG, PNG, TIF, TIFF, PCX, TGA, BMP, WMF, EMF, PSD, WBMP, GIF, TLA, and PDF.
Note that enabling this feature on existing Archives does not trigger PDF conversion on documents already in the system. If you need to perform a mass conversion of documents already present in an Archive, there are a number of ways to achieve this result, but their impact on the system should be carefully considered. Please contact Square 9 Software Support if you need assistance with understanding how best to approach this type of configuration in your specific environment.
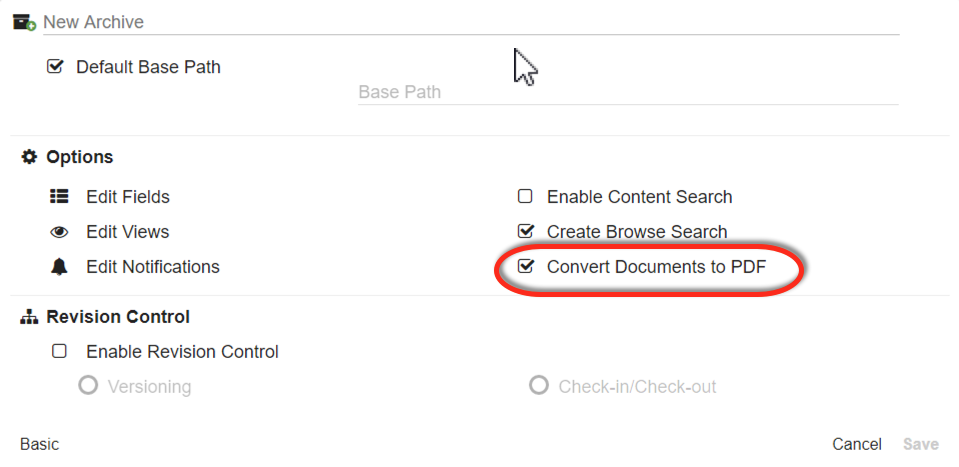
To enable converting documents to text-editable PDF when creating a new Archive, enable Convert Documents to PDF in the New Archive dialog.
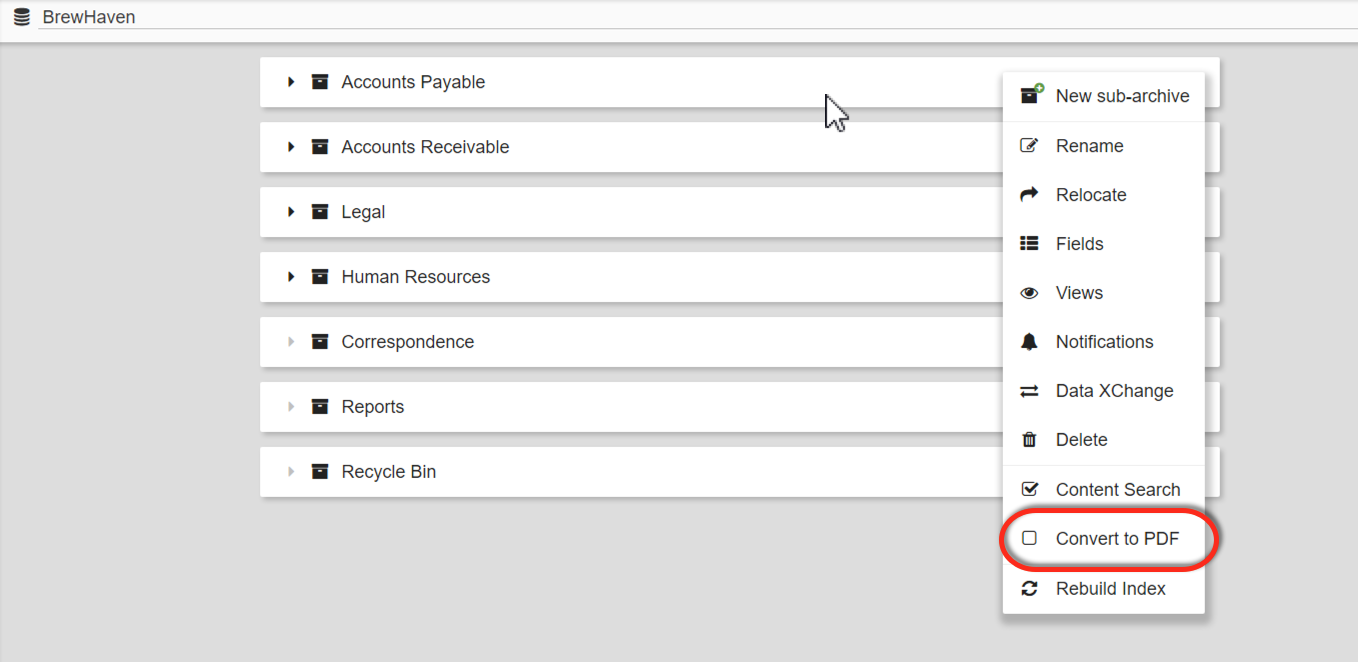
To enable converting in an existing Archive, click Convert to PDF from the More Options () icon for the selected Archive.
JavaScript errors detected
Please note, these errors can depend on your browser setup.
If this problem persists, please contact our support.