SQL Node
Execute SQL statements at any point in a workflow. Data from Process Fields can be injected into the SQL request, and responses can be set back into Process Fields.
The SQL node (formerly SQL Set Field) allows workflow builders to communicate with external data sources for read or write operations.
Supported Database Engines:
Microsoft SQL Server
SQL Connection string parameters can be found here.
PostgreSQL
PostgreSQL Connection string parameters can be found here.

SQL Node Icon
Note, there are minor syntax differences between SQL Server and Postgres. Be sure you SQL is valid for the chosen database backend.
Node Properties
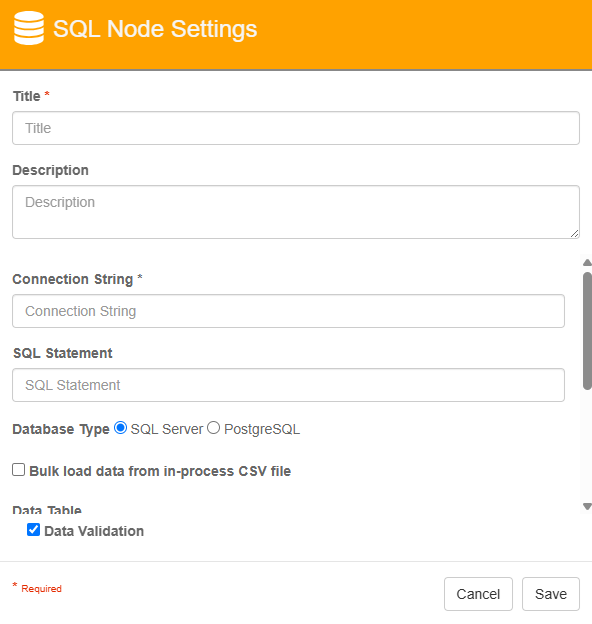
SQL Node Properties
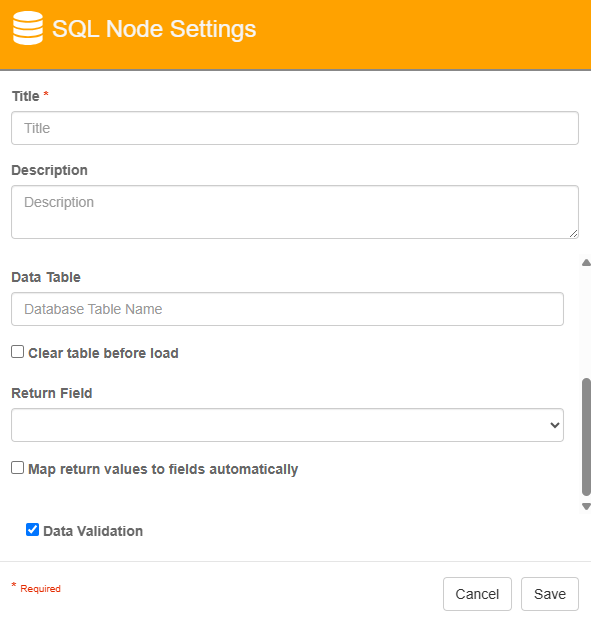
SQL Node Properties cont’d
Title
The Title of your node should be brief but descriptive about what action is being done. Titles are important when revisiting workflows in the future and when migrating workflows. The title of the node will be displayed when resolving conflicts during imports.
Description
The Description of your node should provide notes about this node. This could include information about intended use, details of the SQL connection, etc. Descriptions can be very useful when revisiting workflows in the future.
Connection String
The Connection String determines from where in SQL we want to pull the information. This should include the Data Source and Initial Catalog and any other additional information needed to access the SQL data source.
Ex. Data Source=(local)\SQLEXPRESS;Initial Catalog=SmartSearch;
SQL Statement
The SQL Statement is the SQL query that we can use to pull back information for a specific value. The SQL Statement provided can be any valid SQL Command.
Ex. Select * from [NORTHWND].[dbo].[Suppliers] where CompanyName = 'Tokyo Traders'
Database Type
Select the type of SQL database being accessed. Currently available options are SQL Server (Microsoft) and PostgreSQL (Open Source).
Bulk Load data from in-process CSV
When enabled, the SQL Node will treat the document being processed as a CSV file, then load its contents into the Data Table. Use this feature for automated ingestion tasks.
Imports for SQL Server and PostgreSQL are setup differently. Refer to the configuration details below.
Data Table
The SQL table in which to load the CSV data. New data will be appended to the existing data in the table unless Clear table before load is enabled.
Clear table before load
Clears the values in the data table to which the the CSV is loaded.
Return Field
Responses from SQL commands can be returned back to Process Fields. A Return Field will be set to the return’s first row/column value.
When performing CSV data loads, a Return Field must be set. The Return field will collect the number of rows inserted as part of a data load operation.
Map return values to fields automatically
Fields can be “auto-mapped” when this option is enabled. When enabled, all fields added to the process will be compared to the SQL response. Matching names will have values from the SQL return set automatically.
If the SQL statement queries a table that contains the field Vendor Name and returns a value, it will automatically be returned to a Process Field with the name Vendor Name. This is not case sensitive. I will be added to Vendor Name or VENDOR NAME.
Note that you can write SQL commands to tune the SQL response to meet the workflow’s configuration. A SQL column called id could be auto-mapped to a Process Field named “Employee ID” with a SQL statement like:
select id as [Employee ID] from employees
Important Notes:
Your process must contain only a single file, and that file must be a comma separated list of values.
PostgreSQL and SQL Server handle CSV data ingestion differently. Refer to the Import CSV section for each database type for more detail.
You may not run standard SQL operations and import tasks in a single step.
Import CSV
SQL Server CSV Import
SQL Server handles file imports automatically without any configuration specifics. Make sure your CSV matches the table definition.
PostgreSQL - Loading CSV Data
PostgreSQL has native support for data loads from CSV using the COPY command. A COPY command must be specified for imports. Note this is different than how SQL Server imports work, so be sure you are using the correct configuration for the database platform.
An example copy command:
COPY "<SchemaName>"."<TableName>" (id,name) FROM STDIN WITH DELIMITER ',' HEADERThe CSV file layout should match the field definition specified in the COPY command. In the above example, the CSV is expected to have 2 columns (id and name).
GlobalAction System Values
Please note that these replacement values are case-sensitive
The node has specific support for embedding variables related to GlobalSearch into SQL commands. These variables are:
#ARCHIVEID#
#DOCUMENTID#
#DOCID#
#DATABASEID#
Use these variables in any SQL command when working with GlobalAction processes.
SQL Action Select
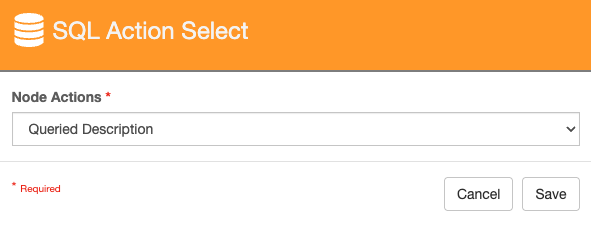
Data Returned
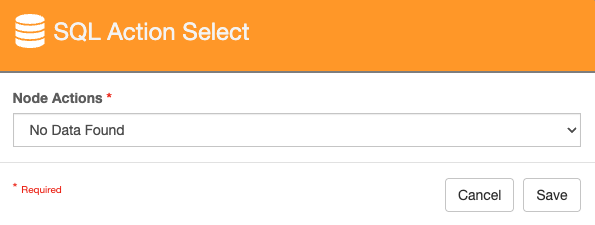
No Data Found
The SQL node requires two outputs: Queried {ReturnField} and No Data Found.
Queried {ReturnField} - This path is followed when at least one return is found form the SQL Query. The {ReturnField} will be populated with the first result. If Map Return Values to Field Automatically is enabled, data will be mapped accordingly.
No Data Found - This path is followed when the query returns nothing.
Use Cases
Backfill Vendor Information
In this example, I've configured the SQL node to pull vendor information from the Northwind SQL database.
This is useful for automatically querying a SQL database and table, without having to run Scheduled SQL Tasks or worry about user interaction.
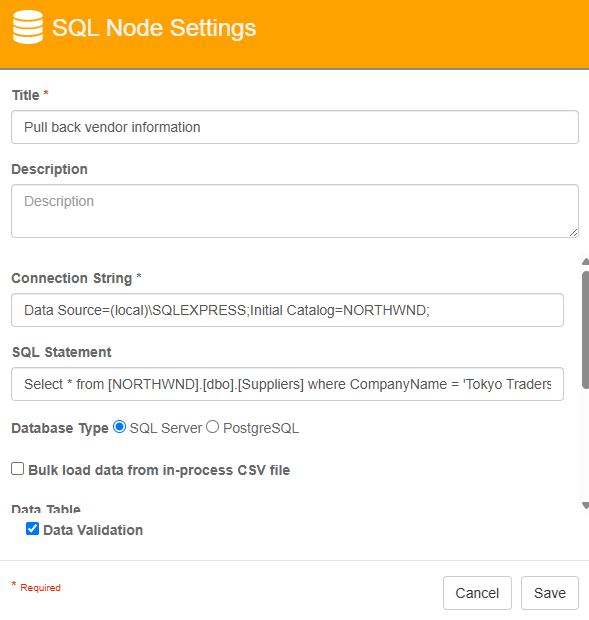
Node Properties Example
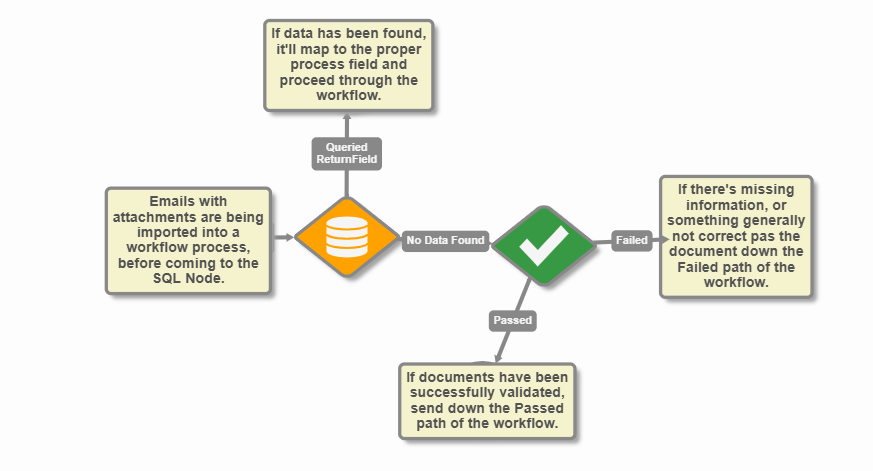
Workflow Example
Query a GlobalSearch Database
To have more control over a data lookup into the GlobalSearch database use the SQL node with a more specific query. Here we are using the Tenant ID to pull back the Tenant Name and Email from the Property Barn GlobalSearch database.
Select Field13 as [Tenant Name], Field3 as [Tenant Email] from [PropertyBarn].[dbo].[ssFields] where Field15 = {p_Tenant ID}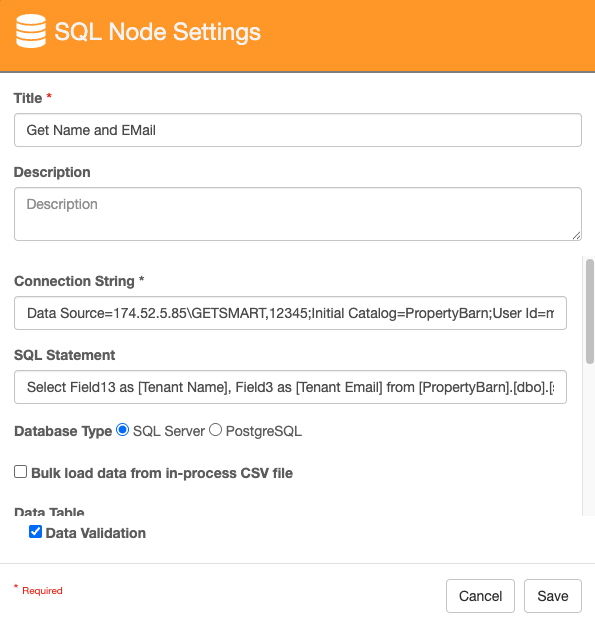
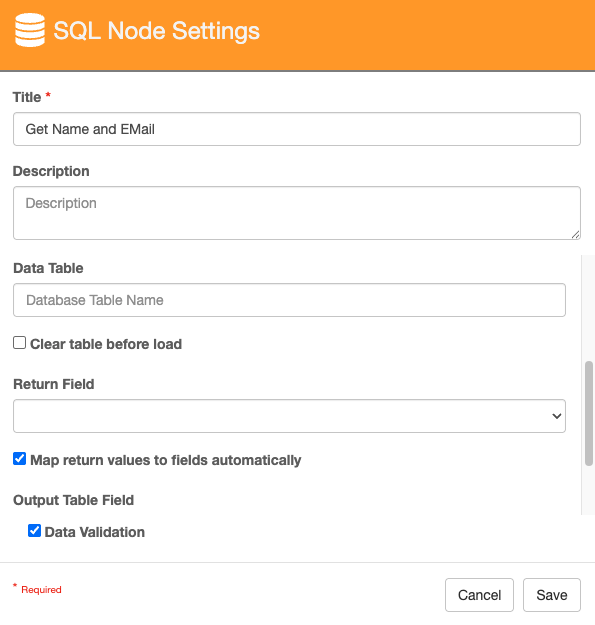
Configure a connection string to your GlobalSearch database.
For Square 9 hosted GlobalSearch in the Cloud databases, please submit a Square 9 support ticket to obtain a connection string. Please include the database(s) to connect to and whether you need read or read/write access.
Write your SQL Query.
For GlobalSearch database lookups:
Standard Index Fields can be found in ssFields.
Multi-Value Fields can be found in ssMVFields.
Table Fields can be found in ssTableFields.
The field names in the table are not the index field names. Field names follow the format Field##, where the ## represents a number. The field number can easily be obtained from the field catalog.
Login to GlobalSearch and select Administration (
 ) from the Administration (
) from the Administration (  ) menu.
) menu.
In the left pane, select Field Catalog.
On the Fields tab, select the correct database. (Or select Table Fields if looking for a Table Field ID.)
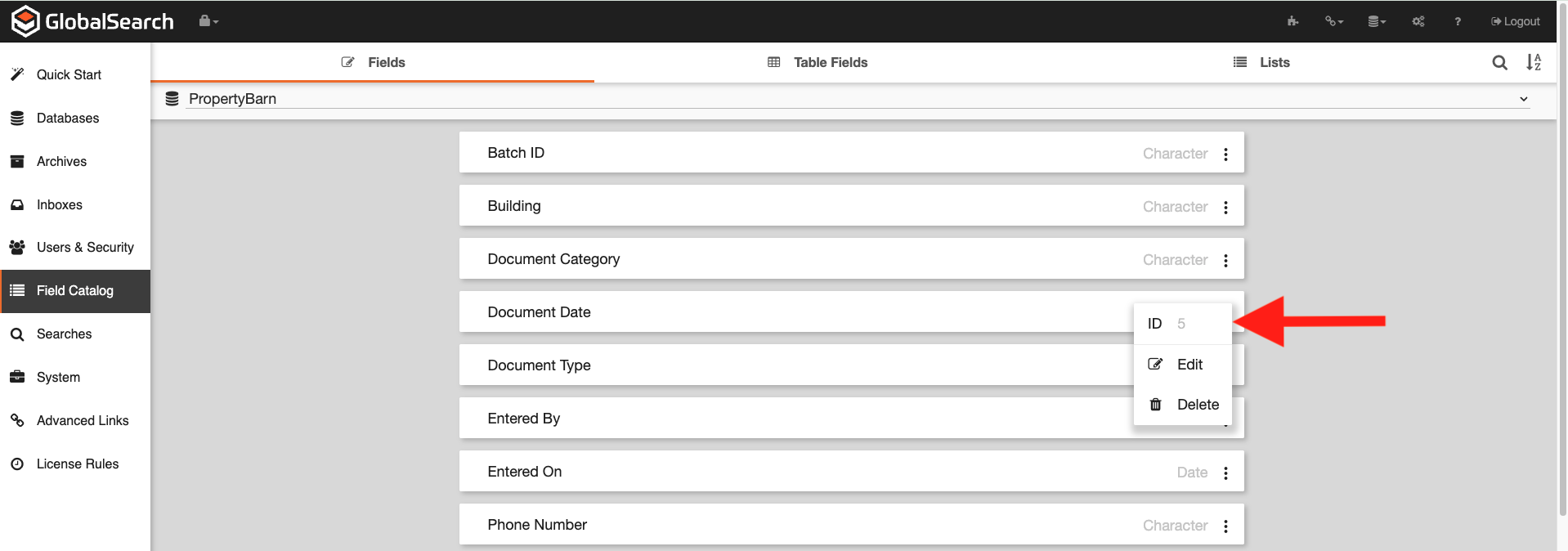
Click the Ellipsis (
 ) next to the field of interest.
) next to the field of interest.The ID is the field number. In the image below, the Document Date index field is Field5 in the ssFields table of the database.
If using Map Return Values to Field Automatically to allow for the return of multiple values, the field names in the SQL table must match the Process Field names. Since the GlobalSearch database idenifies field in the format Field##, the query must cast the database field name to the process field name.