SQL
Execute SQL statements at any point in a workflow. Data from Process Fields can be injected into the SQL request, and responses can be set back into Process Fields.
The SQL node (formerly SQL Set Field) allows workflow builders to communicate with external data sources for read or write operations.
Supported Database Engines:
Microsoft SQL Server
PostgreSQL
Configuration
Basic configuration requires a connection string, a SQL Command, and a chosen database instance type.
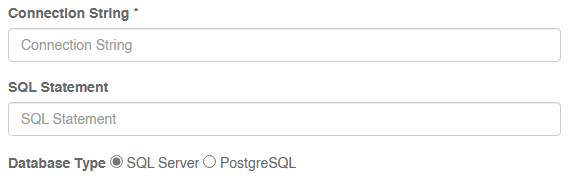
SQL Connections are proxied through the .NET SQL Client library. Connections strings should be formatted in a manner supported by this connection protocol. SQL Connection string parameters can be found here.
PostgreSQL connections are proxied through NpgSQL. Connection string parameters can be found here.
The SQL Statement provided can be any valid SQL Command.
Note, there are minor syntax differences between SQL Server and Postgres. Be sure you SQL is valid for the chosen database backend.
Return Data
Responses from SQL commands can be returned back to Process Fields.
In the node settings, set a Return Field. Return Field will be set to the return’s first row/column value. When performing CSV data loads, Return Field MUST BE SET. Return field will collect the number of rows inserted as part of a data load operation.
Fields can be “auto-mapped” when the option is checked on the node’s settings dialog. With this option set, all fields added to the process will be compared to the SQL response. Matching names will have values from the SQL return set automatically.
Note that you can write SQL commands to tune the SQL response to meet the workflow’s configuration. A SQL column called id could be auto-mapped to a Process Field named “Employee ID” with a SQL statement like:
select id as [Employee ID] from employeesStarting in version 1.3, the Node Settings value for Return Field is no longer required as a result of this behavior.
Importing Data
An option is available to indicate the node should attempt to ingest the document from the process as a CSV file and use that CSV data to load data into a target table. Use this feature for automated ingestion tasks.
Your process must contain only a single file, and that file must be a comma separated list of values.
PostgreSQL and SQL Server handle CSV data ingestion differently. Refer to the Import CSV section for each database type for more detail.
You may not run standard SQL operations and import tasks in a single step.
Imports for SQL Server and PostgreSQL are setup differently. Refer to the configuration details below.
SQL Server CSV Import
SQL Server handles file imports automatically without any configuration specifics. Make sure your CSV matches the table definition.
PostgreSQL - Loading CSV Data
PostgreSQL has native support for data loads from CSV using the COPY command. A COPY command must be specified for imports. Note this is different than how SQL Server imports work, so be sure you are using the correct configuration for the database platform.
An example copy command:
COPY "<SchemaName>"."<TableName>" (id,name) FROM STDIN WITH DELIMITER ',' HEADERThe CSV file layout should match the field definition specified in the COPY command. In the above example, the CSV is expected to have 2 columns (id and name).
GlobalAction System Values
Please note that these replacement values are case-sensitive
The node has specific support for embedding variables related to GlobalSearch into SQL commands. These variables are:
#ARCHIVEID#
#DOCUMENTID#
#DOCID#
#DATABASEID#
Use these variables in any SQL command when working with GlobalAction processes.
Node Download
Version 1.5 of the node can be downloaded from the Node SDN.