PDF Redaction Node
This node is available for GlobalCapture workflows only and is available for download from the Square 9 Solutions Delivery Network.
The PDF Redaction node is used to permanently obscure any text matching a specific pattern in a document. Any valid regular expression can be provided to the node.
All matches, across all pages, will be permanently removed from the document, including any text layer data in the PDF.
All documents must be in PDF format, and be text-searchable to be processed by this node.

PDF Redaction Node icon
Depending on the application that generated the PDF, the text layer may not line up properly with the image on some PDFs. In such cases, use a PDF Convert node. Square 9’s PDF generator can reliably position the image under the text for image based PDF files.
Note that vector based (all text) PDF files and image over text based PDF files will present redactions differently. With a vector/text based PDF, the data is removed and will appear blank. With an image over text PDF, the data is removed, and a black redaction will be added to the image layer to obscure the text of the image itself.
Node Properties
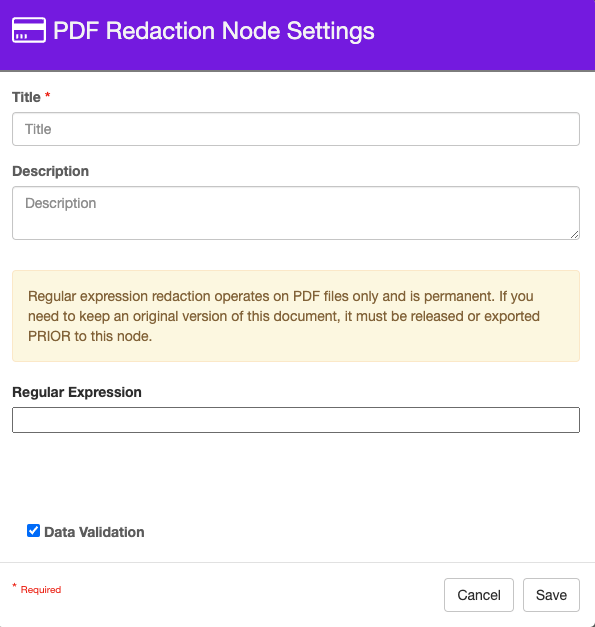
PDF Redaction Node Settings
Title
The Title of your node should be brief but descriptive about what is being redacted. Titles are important when revisiting workflows in the future and when migrating workflows. The title of the node will be displayed when resolving conflicts during imports.
Description
The Description of your node should provide notes about this node. This could include information about data being redacted.
Regular Expression
Regular Expressions, also know as RegEx, is where you can specify what string of text we want to redact using a RegEx formula.
For more information regarding regular expressions, please refer to the knowledge base, “Regular Expressions”.
Example Patterns | |
|---|---|
Social Security Number ###-##-#### | \d{3}-\d{2}-\d{4} |
US Phone Number (###) ###-#### | \(\d{3}\)\s?\d{3}-\d{4} |
US Federal Tax ID ##-####### | \d{2}-\d{7} |
Data Validation
Data Validation checks to ensure data being added to an index field conforms to the field’s properties such as length and data type. When enabled, a process error will occur if there is a mismatch. If disabled, data will populate the field even if there is a mismatch.
If disabling, there should be a validation step as documents with invalid data formats will error on release to GlobalSearch.
Ex. A numeric field only contains numbers, no letters or symbols.
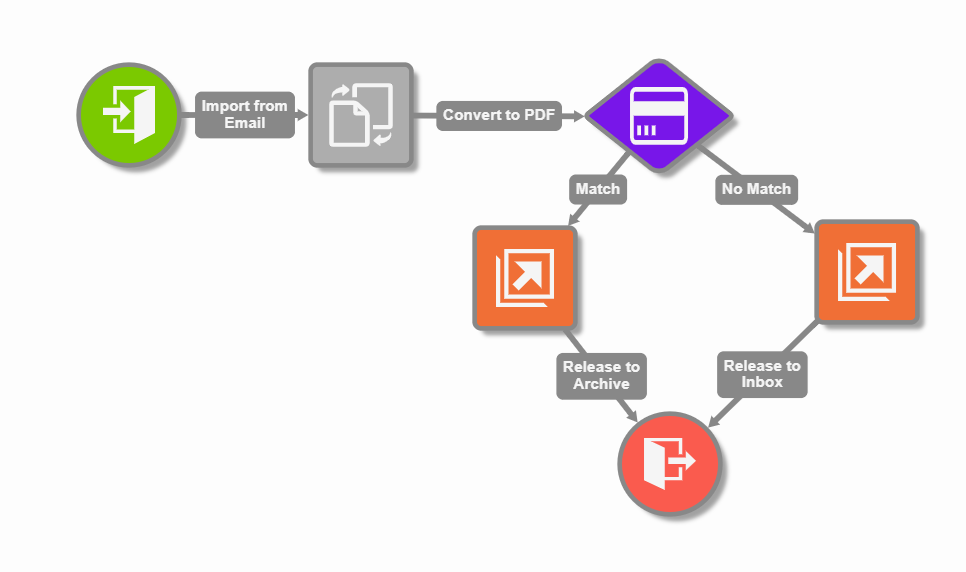
PDF Redaction Match Paths
Two output paths exist for the node.
Match status implies the document was processed and at least one occurrence of the pattern was found and redacted.
No Match status means no results were found matching the pattern on any pages.
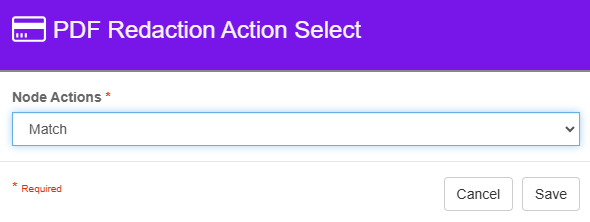
PDF Redaction Action Select - Match
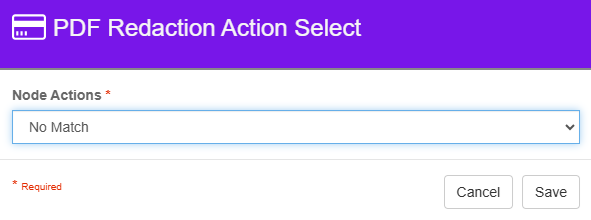
PDF redaction Action Select - No Match
Use Cases
Redacting a Social Security Number
In this example, I've configured the PDF redaction node to redact any documents that contain a social security number in the specific format 123-45-6789. It
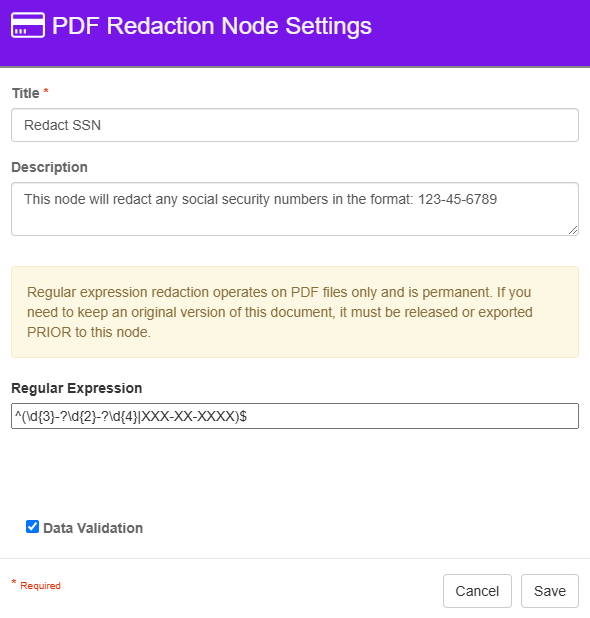
PDF Redaction Node configured to match a SSN
Workflow Example