Rapid Adapt Forms Learning provides a unique means for expanding extraction rules within existing processes so that productivity is maintained, even when new document formats or exceptions in expected data are found.
Building off the concept of document classification, Rapid Adapt Forms Learning recognizes a document through predefined attributes and applies a corresponding extraction template. When a new document does not match existing extraction rules, validation users can use Rapid Adapt to build a reusable template on the fly. The packaged solutions for AP and AR demonstrate the how to implement Rapid Adapt logic into your own processes.
How it works
When an OCR template is created, one or more “Marker Zones” are designated. This create a unique handprint of the document so it can be quickly identified and classified.
As documents are routed through the classification and extraction phase, any processed records that have corresponding markers are recognized, classified and their data is extracted. Any unmatched documents are routed to the Rapid Adapt Forms designer.
Through this wizard like interface, a user creates both Marker and Positional Zones to create a new template with little to no effort.
After saving, the document is re-routed through the classification engine where it and any future instances of this document format will be automatically processed for classification and extraction.
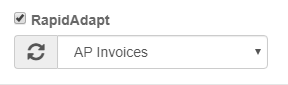
Any Validation user can use Rapid Adapt, but the feature is generally reserved for trained and/or power users of the system. Rapid Adapt is enabled in a specific Validation step by checking the RapidAdapt button and selecting a Template Group in the Node's settings.
Using RapidAdapt Forms Learning
When a document reaches a Validation Node with RapidAdapt enable, the user can click the flame icon above the indexer to begin the Forms Learning process.
Start by selecting one or more markers to uniquely identify the document. Click and click a word in the document. When you click Add Marker for the first time on a document, there may be a slight delay as the OCR data loads into the browser. It is important that all markers are both unique to the document, and will appear on all subsequent documents. Continue adding Markers, or click Next.
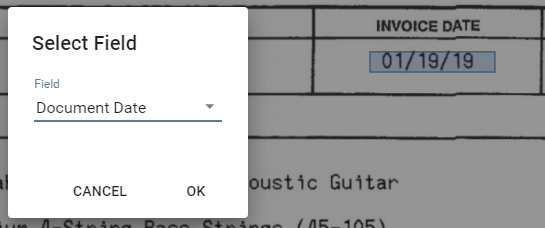
Add zones to extract by clicking and use the mouse to draw a box around a data point in the document viewer. In this example, a box is drawn around the Invoice Date value, and the data will be assigned to the GlobalCapture process field named Document Date. Repeat this process for all fields that should be extracted.
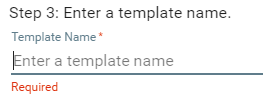
When all fields have been added, click Next to provide a unique name that will correspond to this document. If this were a vendor invoice, you might want to name it with the Vendor's name.
When a name is provided, the button will be enabled. Click it to commit changes to the system.
Once the Forms Learning process is complete, the user will be back in the standard Validation station. Depending on how the workflow is setup, at this point the document may be manually indexed, or the document may be sent back into the workflow to be extracted automatically by the rules that were just defined. To understand workflow best practices, it is recommended administrators review the sample processes linked above.
JavaScript errors detected
Please note, these errors can depend on your browser setup.
If this problem persists, please contact our support.